Gemini Multimodal Launch
Videos to introduce multimodal AI (faced criticism)
| Year | 2023 |
| Location | |
| Tags | AI, Film |

In December 2023, Google launched Gemini, a multimodal AI model that could understand and generate text, images, and audio.
I worked on the small team tasked to create a series of promotional videos for the launch. Multimodal AI was a new and complex concept, so we had to create a series of videos that would explain the technology to a wide audience.
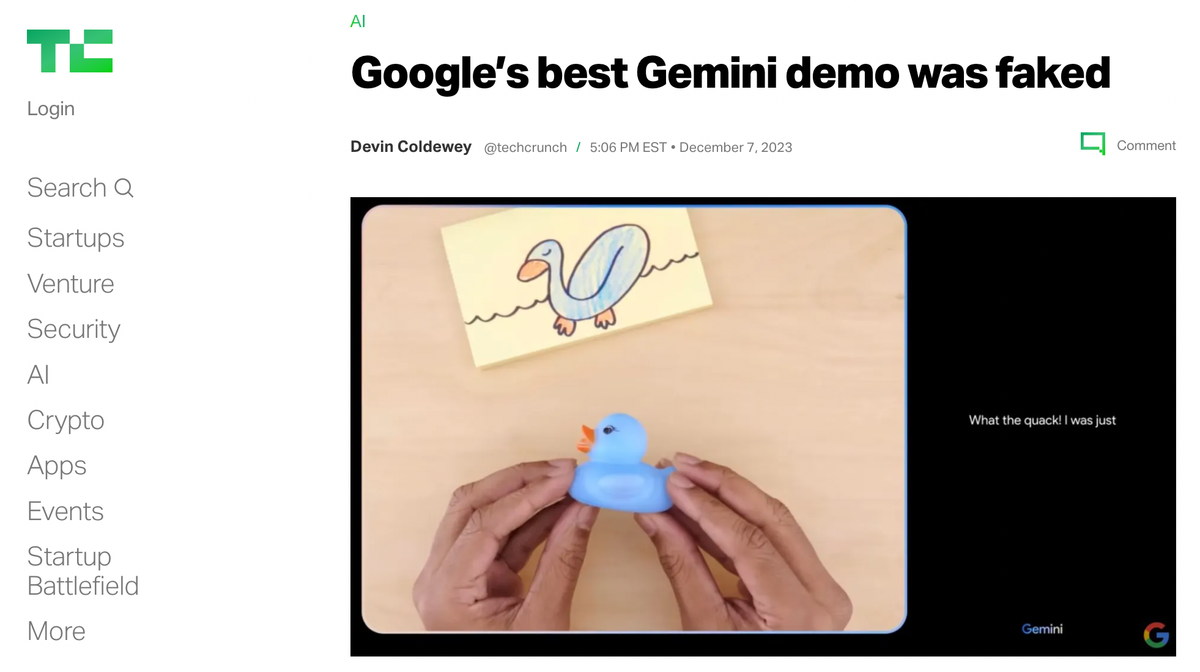
The launch was an overnight success. However, the launch video's popularity was followed by a wave of scrutiny.
In the video, it was unclear that the prompts voiced aloud were abridged versions of the actual prompts sent to the model. The underlying prompts for anyone to recreate the results are outlined in this developer post.
Media Coverage
- BBC - Google admits AI viral video was edited to look better
- Wired - Google Just Launched Gemini, Its Long-Awaited Answer to ChatGPT
- Bloomberg - Google’s Gemini Looks Remarkable, But It’s Still Behind OpenAI
- Techcrunch - Google’s best Gemini demo was faked
- CNBC - Google faces controversy over edited Gemini AI demo video
- Business Insider - Turns out Google's Gemini demo wasn't nearly as amazing as it seemed
- Fortune - Google VP Sissie Hsiao: The Gemini AI demo video ‘is completely real,’ though Google ‘did shorten parts for brevity’
- Gizmodo - Google Definitely Had Its ‘Hands-On’ That Gemini AI Demo
- Yahoo Finance - Google Definitely Had Its ‘Hands-On’ That Gemini AI Demo
- The Verge - Google just launched a new AI and has already admitted at least one demo wasn’t real
- Popular Science - Google announces Gemini, its ‘multimodal’ answer to ChatGPT
- CNET - First Impressions of Gemini: Google's Newest Major AI Upgrade
- The New York Times: HardFork Podcast - Googles Next Top Model, Will the Cyber Truck Crash? and This Week in A.I.
- Business Today - Google Gemini’s viral video showcasing AI powers was not done in real-time or using voice commands
- MKBHD - 2024 Tech I'm Ready For! (The biggest tech focused youtube studio/channel in the world)
- WaveForm Podcast: Podcast from the biggest tech focused youtube studio/channel in the world)
Personal Note
I am EXTREMELY glad news outlets were criticizing this launch. I believe it's important to hold companies accountable for their claims, especially when it comes to introducing complex technology.
It shifted my values from making AI feel magical -> towards making it feel approachable.
Another series of videos from the launch (facing less scrutiny) were 1 minute videos demonstrating novel AI use cases, like picking an outfit or combining different emojis.
I was responsible for concepting, scripting, and voicing the use case video for coding. I personally love fractal trees... especially ties between biomimicry and code, so I made a video highlighting the model's ability to generate code by bridging patterns across different domains.
← Back